JSTQB Foundation Level を取ってみた
JSQTB Foundation Level というソフトウェアテストに関する資格の一番基礎的なものを取ってみた。
数年前からテストのメンテナンス性に難を感じていて Unit Testing Principles, Practices, and Patterns や The Art of Unit Testing を読んでみたもののどうもしっくりせず。そこでそもそも自分はテストというものが何なのかよくわかっていないのではと思い「テスト」自体について勉強することにした。なにか目標があったほうがモチベが保ちやすいので資格について調べたら JSTQB FL を発見。社内の QA の人に聞いたら QA が資格取るとしたらまずこれということだったので受けることにした。
")
")
勉強法
まずはどんな問題が出るのか知りたかったので問題演習ができるテス友をやってみた。新たに勉強しなくても7割くらいは取れた。なおテストの知識がなくても現代文、算数、汎用的な試験のテクニックで5割は取れると思う(単なる工数の計算や論理的にありえないものを消去したりでテストの知識がいらないもの多数)。65%で合格なので安定して80%の得点を目標にした。
自分の実力がわかったあとはシラバスを notebooklm に取り込み各章の音声解説を作らせ暇な時間に聞いてどういうことが求められているのかの概要を覚えた。シラバスに関してはこの音声解説がメインで通読は結局しなかった。
シラバスでは具体例が乏しいので JSTQB を運営している ASTER のオンラインセミナーも視聴した。
経験者はシラバスとテス友だけで受かったという人も多くいたが、QA の人たちの話であって私は QA ではないのでさすがに本を1冊くらいは読んだほうが良かろうと思いソフトウェアテストの教科書を読んだ。Foundation Level の内容を超える内容であったがテストドキュメントなるものがどのようなものなのか具体例があって理解の助けになった。
![【この1冊でよくわかる】ソフトウェアテストの教科書 [増補改訂 第2版]](https://m.media-amazon.com/images/I/41TNqyMXGCL._SL500_.jpg "【この1冊でよくわかる】ソフトウェアテストの教科書 [増補改訂 第2版]")
受験
多分受かると思うけど落ちると3ヶ月再受験ができないということに日和って何度もリスケジュール1をしたが腹をくくって受けてきた。 Peason Vue のページに書いてある通りラミネート加工したホワイトノートとペンが渡されて計算に使ったが、てっきりホワイトボードのように消せるのかと思ったら一度書いたら消せない仕様で半分くらい使ったところで焦った。多分頼めば追加がもらえると思うけれど。
8問が2択まで絞ったけれど自信ない感じに。一応、他が全問あっていればこの8問が全問不正解でも受かる計算なので多分大丈夫だろうと思いながら試験会場をあとにした。
合格発表
受験から3日後、メールで結果が出た旨の通知が来たので確認したら合格だった。 合格するとは思っていたが同僚にも受けることを公言していたおり、落ちたら恥ずかしいと思っていたので合格でホッとした。
- 受験日は予約後も変えられる↩
3年8カ月ぶりに AtCoder 水色になった
ABC 420 にて3年8ヶ月ぶりに AtCoder Algorithm で水色になった。 G 問題をまぐれで通したら過去最高パフォーマンスの1801が出てレートが一気に上がった。
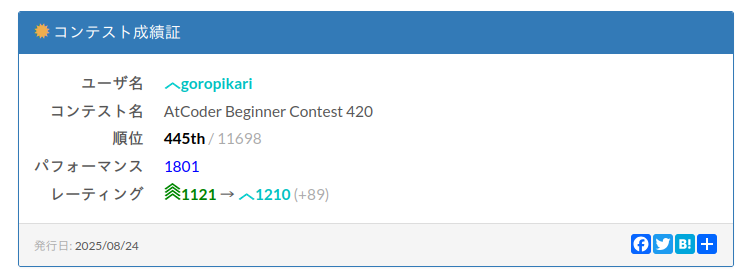
https://atcoder.jp/users/goropikari/history/share/abc420
はじめに水色になったのは平成最後の AtCoder の頃でその頃は ABC が4問体制、Rated 範囲が 0〜1199 で比較的パフォーマンスが出やすかった。今と違って AGC にも誰でも出れることができ最初のA問題を解けば水色パフォーマンスが出るような時代だったため今よりもレートは上げやすかったように思う。 水色になってからはこの肩書を捨てたくない一心で rated 参加から逃げ続け、そのうち AtCoder 自体もやらなくなり形ばかりの水色コーダーとして数年過ごした。一念発起し再開し緑に。出れば出るほど下がっていくレートに耐えられなくなりまた休止。
年始に今年は資格などを取り自分の実力をちゃんと客観的に評価できるようにすることを目標にした一環で AtCoder もいつまでも過去レートにすがりつくのはよくないと思い立ち再開。再開を決断できたのは歳を取って自分の弱さを受け入れられるようになったということもある。
基本的に毎週 rated で出た結果、一時はレートが 1001 まで落ちた。3桁レートも覚悟したがそこから何とか巻き返し徐々にレートが上がってきた。6年前に水色になったときよりも明らかに今の自分のほうができる感覚はあったものの、パフォーマンスが自分のレートとだいたい同じところになることが多くこの辺が自分の限界かと思っていたが今回期せずして水色に戻ってこれた。
といっても今回の ABC 420 で通した G 問題は適当に式変形して WA 前提で提出したらまぐれで AC してしまったので実力で取れたとは言い難いのが悔しいところ。前回の ABC 419 ではパフォーマンス 908 と出力が全然安定していないのでまずは安定して水色パフォが出せるようにしていきたい。
数学検定準1級を受けてみた
今年のはじめから数年ぶりに AtCoder を再開し、そのために数学の復習も始めた。せっかく勉強するのならば何かしら目標があったほうがよいと思ったため数学検定を受けることにしてみた。 1級の範囲である理系の学部1, 2年次くらいの数学は時間をかけて復習し直さないと受かりそうになかったので、過去問をみてそれなりに解けそうだった準1級を受験することにした。
準1級
準1級は高2〜3の範囲がメイン。大学入試ほどひねった問題が出るわけではないので難しいという感じはしないが、手で計算するということを長らくしていなかったせいでとにかく計算ミスをしてしまう。過去問演習でも制限時間の半分くらいで全問解き終わるがミスで8割方間違えることも。特に1次は答えのみ回答で部分点がもらえないので計算ミスが致命的になる。 それと2次試験は電卓を使ってよいが生まれてこの方数学の試験中に電卓を使ったことなかったので抵抗感があって慣れなかった。
試験当日
B日程だと試験会場を選べるので近所の会場を選択。私が選んだ会場はすべての級が同じ部屋で一斉に受けるスタイルだった。小学校低学年位の子が2級(高1,2レベル)を受けていて世の中の広さを感じた。
1次も2次も試験時間の半分ほどで解き終わったが見直したら予想通り計算ミスをたくさんしていた。横目に途中退席する他の受験者を見送りつつ、私は最後の最後まで検算をしていた。 B日程だと問題も回収され、自己採点ができないので、多分受かっていると思うけどもしかしたら落ちているかもと合格発表までの2週間強をもんもんと過ごした。
結果
無事に合格していた。1次は2問を確実に落としたと思っていたが蓋を開けてみたら1問間違えで、2次は論証が甘くて減点されるかもと思った証明問題は完答して自信があった計算問題で減点されていた。
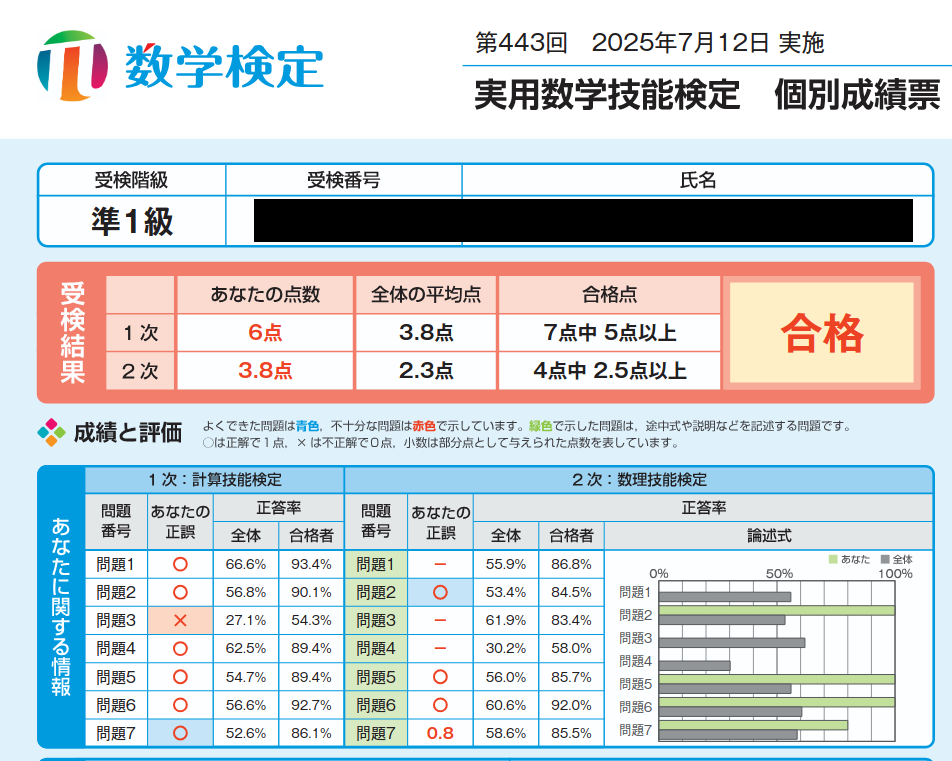
今後この資格が何かの役に立つということは無いと思うけれど、受験数学に出ないからと勉強していなかった分野をちゃんと学んだり、公式として丸暗記していたものを自分で導出したりと、過去にいい加減に勉強していた分野を学び直せたのは結構良かったと思う。
勉強に使った教材

過去に準1級の範囲をすでに学んだことがある人なら丁度いいボリューム感の本だと感じた。 例題含めれば問題数もそこそこあり問題集として私は使っていた。 数学検定の公式のテキストの割には証明が雑すぎると感じるが総合的には使いやすいと思う。

要点整理だけでも十分と思ったけれど一応過去問も解いた。試験問題の傾向を多少掴めた。 買わなくても多分困らないけど、実際の試験時間で解く練習にはなった。
他にも数研出版の青チャートも買ったけれど結局やらなかった。
電卓
2次の計算は電卓がなくてもこなせる程度なので関数電卓ほど高機能なものが必要かと言われると微妙だが、分数で計算できたり定積分を計算できたりするので検算のときにあると便利だった。
私が購入したのはこれ
")
受ける前は関数電卓の持ち込み ok となっているけど機能に関する記述がなかったのでどこまで高機能のものを持ち込んでいいのか不安だったが、電卓の機能に関するチェックもなかったのでネットに繋がらなくて見た目がよくある電卓であればどれだけ高機能でもよさそうな印象だった。
Neovim で clangd を使うと trying to get AST for non-added document と出て clangd が機能しなくなった
日本語を含む C++ のソースコードを Neovim で編集していると -32602: trying to get AST for non-added document というエラーが出てそれまで diagnostic や code format が効いていなのに突然効かなくなる現象に悩まされるようになった。
日本語が含まれているのが原因っぽい感じがしたがファイルを開いた直後だと効いていて、無駄な改行などを入れてファイル保存するとそのうち上記のエラーが出て機能しなくなってしまう。
mason-org/mason-lspconfig.nvim を辞めて素の Neovim の LSP の機能だけで完結させようと移行をしたらこの現象が起きるようになったのでなにか設定が悪そうなことは想像できたが LSP の log を見てエラーを文でググってみても解決になりそうな情報にはたどり着けず。
いろいろ試した結果 offsetEncoding で utf-16 だけを指定してみたらエラーで落ちることはなくなった。nvim-lspconfig のデフォルト値である {'utf-8', 'utf-16'} だとこのエラーに悩まされる。
治ることには治ったがなぜ治ったのか理由はよくわからない。
return { cmd = { 'clangd', '--background-index', '--clang-tidy', '--header-insertion=iwyu', '--completion-style=detailed', '--function-arg-placeholders', '--fallback-style=google', }, capabilities = { offsetEncoding = { 'utf-16' }, textDocument = { semanticTokens = { multilineTokenSupport = true, }, }, }, }
10年以上使った ArchLinux から Ubuntu に移行した
年末辺りに使用していた ArchLinux の動きが怪しくなり始め、なんの前触れもなくフリーズすることが多くなった。デュアルブートしている Windows では問題は起きなかったのでおそらくハードウェア起因ではなさそうだった。kernel のせいかなと思い LTS 版に切り替えようとしたが失敗してとどめを刺した。
仕事では WSL を使って開発しているのでいっそ Linux 自体をネイティブに入れるのを辞めることも検討したが i3wm に体が慣れすぎていて辞めるのは無理だった。
boot 領域だけ直せばまた元通りに使えそうではあったが、インストールから数年たちゴミも増えていたのでクリーンインストールすることにした。 再び ArchLinux を入れることも考えたが GUI インストーラーもなくひたすらコマンドを打ってインストールする活力もなく、以前ほど ArchLinux にこだわる理由もなくなってしまったので安定してそうな Ubuntuにすることにした。
あまり覚えていないが元々 ArchLinux を使っていたのはソフトが最新であるということと自分で入れたものしかないので無駄がなくてシンプルだからという理由だった気がする。ArchLinux を使う前は Ubuntu や LinuxMint を使っていたがソフトが古くてやりたいことができなかったり、無駄と思ってたソフトを消したら動作が不安定になったりしてカスタマイズがし辛いと感じていた記憶がある。
時が経ち、Docker を覚えてからは最新のソフトのお試しはローカルにインストールすることなくコンテナの中で済ますことが多くなった。 さらに Devcontainer を覚えてからは開発環境をコンテナの中に作るようになったおかげで Linux Distribution に求めることは安定して Docker が使えてあとはタイル式 window manager が使えればよいという価値観に変わった。 このような価値観の変化から ArchLinux にこだわる理由が私の中ではなくなってしまい、頑張らなくても安定して使えるものが欲しくなった。
そんなこんなで安定といったら Ubuntu かな?ということで Ubuntu にした。始め素の Ubuntu に i3wm を入れてみたが動作が安定せず、最終的に Ubuntu Sway Remix を使うことにした。デフォルトの機能を無効にしていく作業に多少てこずったが実用に困らない程度には設定をいじることができた。 i3wm の操作感を踏襲しつつ、GUI っぽい操作も両立しててとても印象が良い。今までほぼ素の i3wm を使っていたせいでマウス操作で雑にこなしたいときも常にキーボードを使わなければならなかったところが、マウスも普通に使えるようになって利便性が格段に上がった。
X から Wayland に変わって今まで使っていたソフトのいくつかは使えなくなってしまったが、使用頻度の低いものだったので今のところそれほど困っていない。
移行記録は zenn のスクラップにつらつら書いている
https://zenn.dev/goropikari/scraps/6fe6fdcc9bd6ad